Making a Jamaican Creole Dictionary: Word Frequency
Previous Post In the last post, we created a list of words in a text file that contains each word used exactly once. Since we might be interested in which words occur frequently or infrequently in our source text, we’ll look at how to associate a count with each word in our list. We’ll also look at how to create a DataFrame, which we’ll use to store other useful information about the words in the list.
To begin, let’s remind ourselves of how we created the word list in the first place:
with open('JCR_words.txt', 'w') as f:
for book, num_chapters in book_num_chapters.items():
for chapter in range(1, num_chapters + 1):
url = f"https://www.bible.com/bible/476/{book}.{str(chapter)}.JNT"
req = Request(url, headers={'User-Agent': 'Mozilla/5.0'})
page = urlopen(req).read()
soup = BeautifulSoup(page, 'html.parser')
verse_elems = soup.find_all('span', class_='content')
for verse_elem in verse_elems:
verse_text = verse_elem.text.split()
for word in verse_text:
words.append(''.join(filter(str.isalnum, word.lower())))
words = sorted(list(set(words)))
for word in words:
f.write(word + "\n")
Counting Frequencies
To build on what we have, all we need to do is record the number of times each word is seen. One way to achieve this is by using a dictionary that maps a word to the number of times that it appears. If the word is already in the dictionary then we can increment its count, if not, we can add it to the dictionary with a count of 1.1 Recall that in the last post, we normalized the words by making them all lowercase, which will avoid the problem of having capitalized words included twice.
frequencies = {}
words = []
frequencies = {}
with open('JCR_words.txt', 'w') as f:
for book, num_chapters in book_num_chapters.items():
for chapter in range(1, num_chapters + 1):
print(chapter)
url = f"https://www.bible.com/bible/476/{book}.{str(chapter)}.JNT"
req = Request(url, headers={'User-Agent': 'Mozilla/5.0'})
page = urlopen(req).read()
soup = BeautifulSoup(page, 'html.parser')
verse_elems = soup.find_all('span', class_='content')
for verse_elem in verse_elems:
verse_text = verse_elem.text.split()
for word in verse_text:
clean_word = ''.join(filter(str.isalnum, word.lower()))
words.append(clean_word)
if clean_word in frequencies.keys():
frequencies[clean_word] += 1
else:
frequencies[clean_word] = 1
words = sorted(list(set(words)))
Creating a DataFrame
Now that we have some interesting data about each word, we can start to fill in a DataFrame. This data structure allows us to store the words and some of their atrtributes in a table-like structure, which will prove useful in the future when we want to add additional data about each word. This data structure will also make it really easy to save our findings to a file that can be reused in the future so that we don’t need to make an API call every time (our text file served us well but this is more legit 😎).
DataFrame is a part of the panda module so we need to be sure to import that:
import pandas as pd
...
Then we can put the data from our dictionary into a new DataFrame:
words = []
frequencies = {}
with open('JCR_words.txt', 'w') as f:
for book, num_chapters in book_num_chapters.items():
for chapter in range(1, num_chapters + 1):
print(chapter)
url = f"https://www.bible.com/bible/476/{book}.{str(chapter)}.JNT"
req = Request(url, headers={'User-Agent': 'Mozilla/5.0'})
page = urlopen(req).read()
soup = BeautifulSoup(page, 'html.parser')
verse_elems = soup.find_all('span', class_='content')
for verse_elem in verse_elems:
verse_text = verse_elem.text.split()
for word in verse_text:
clean_word = ''.join(filter(str.isalnum, word.lower()))
words.append(clean_word)
if clean_word in frequencies.keys():
frequencies[clean_word] += 1
else:
frequencies[clean_word] = 1
words = sorted(list(set(words)))
for word in words:
f.write(word + "\n")
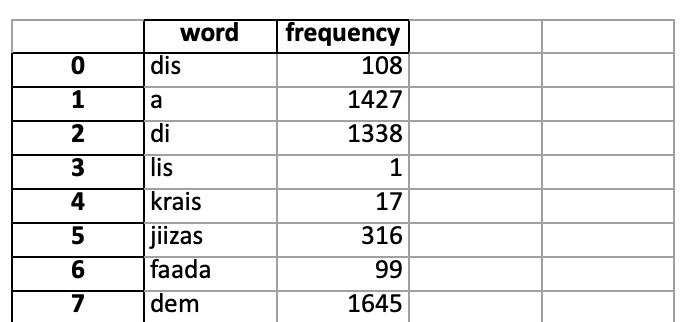
df = pd.DataFrame(list(frequencies.items()), columns = ('word', 'frequency'))
print(df)
word frequency
0 dis 108
1 a 1427
2 di 1338
3 lis 1
4 krais 17
... ... ...
1194 iel 1
1195 ben 1
1196 kuk 1
1197 ilevn 1
1198 evriwe 1
[1199 rows x 2 columns]
The DataFrame has a row for each word and its frequency.
Writing to a File
Since we have our data in something that looks roughly like a table, we might want to export it to an Excel file to do some more interesting things with, and which we can also read back into other programs.
Pandas provides a really simple way to do this:
df.to_excel('frequencies.xlsx')
And that’s it for this post. Next time, we’ll look at how we can generate an index that will tell us which book and chapter each word can be found in.
-
Alternatively, we could have done this all when duplicates had not yet been removed from
words. ↩